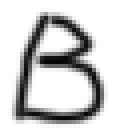
EとHはおまけ(^-^)
VisualStudio + Pythonでディープラーニング
「B」の識別率を上げたい!
(2020. 1. 5)
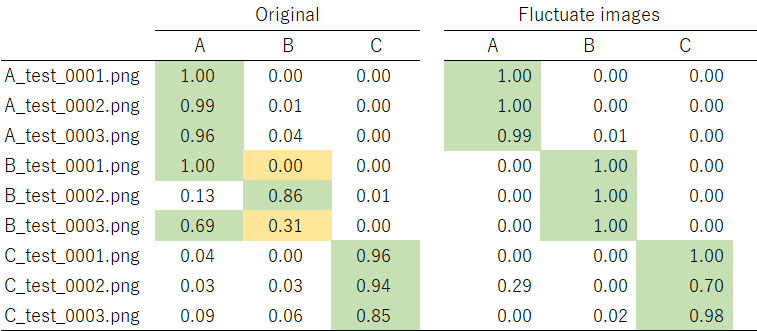
前章で畳み込みニューラルネットワーク(CNN)をKerasで実験してみました。「A」「B」「C」3つのアルファベットのどれかが描かれた画像ファイルを学習してそれを判別できるモデルを作りました。結果、AとCは良好に判別してくれたのですが、Bの判別はちょっと残念な事になりました:
EとHはおまけ(^-^)
テスト画像は32×32のサイズで、
作ったモデルは次のようなものです:
この章では上のモデルをベースにして、Bの識別率を上げるにはどうしたら良いのか?色々と試行錯誤してみたいと思います。
① 学習画像を増やしてみる(Up)
ベースのモデルに使った学習画像は各アルファベットで3000枚、合計で9000枚です。Bの識別率が悪いのであれば、Bだけこれを倍の6000枚に増やしてみます:
お、0003番の画像の識別率が向上しました。しかし0002番は若干A側寄りにシフトした感じです。また0001番は相変わらず自信をもって「Aです!」と宣言。いや、Bだから
orz
彼が自信をもってAだと言い張るB_test_0001.pngは次のような画像です:
んー…まぁ、Aっぽいと言えばAですが、人が見たら100%Bな画像です。ちょっと画面の下側に線があるのが気になります。学習で使用しているBの画像は少し上寄りなので…。そこで、元の学習データの画像をちょっと揺らしてみます。
② 学習画像に揺らぎを与える(超Up!)
学習に使うBの画像をちょっと上下左右にランダムに揺らしてみました。枚数は同じ6000枚です:
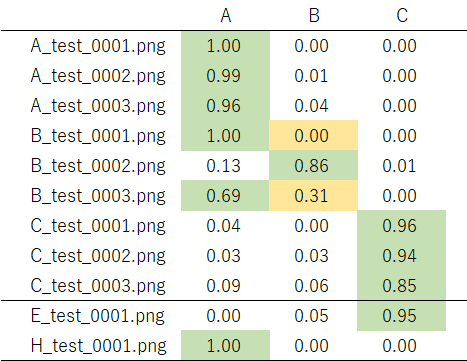
うおー!識別率が爆上がりです!!なるほどぉ、パターンが不足していたのか…。そこで、枚数を3000枚に戻し、揺らぎのみの効果でもう一度試してみます:
うん、枚数を減らしてもBの識別率は向上したままでした。やはり学習データに揺らぎを与えたのは大正解でした。
③ 過学習?(Up?)
扱っている学習用の画像はインストールされているフォントをランダムに選択して作成しています。もしかするとその画像に対して過学習になってしまっているかもしれません。そこで先程までの揺らぎはいったん無くして、代わりにドロップアウトを挟んでみます。挟める場所はFlatten層の後くらいしかありませんので、そこに挿入です。rateは20%位にしておきましょう:
んー、0003番の画像の識別はしっかりBになりましたが、0001番のは変わらずAのままです。推定をさらに緩めるためrateを40%に上げてみます:
変わらず orz。ドロップアウトの効果は一部認められましたが、これは多分0001番を判定する情報が学習データに欠落しているんだろうと感じます。よってそこだけは頑なにAと判定してしまうようです。
④ A、B、C全ての画像に揺らぎを与える
②から画像を揺らす効果はかなり高いようなので、他のアルファベットも揺らしてみます:
ありがとうございますーー!(T-T)/
という事で、前のモデルで今一だった「B」の識別率を上げるために幾つか方策を実験してみました。学習するデータ数を増やす事は勿論大切ですが、「学習データのバリエーション」をちゃんと確保する事が識別率を高めるのに効果的である事が良く分かりました。こういう経験則が後々で生きてくるんじゃないかなと思います(^-^)