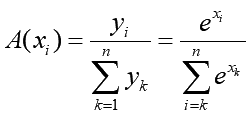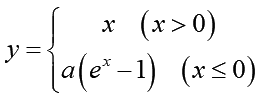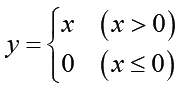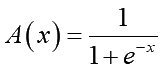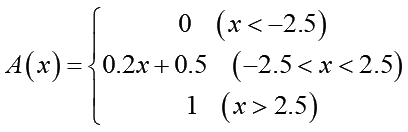VisualStudio + Pythonでディープラーニング
Kerasの活性化関数を知ろう
(2019. 12. 4)
前章ではミニマムなニューロンの処理をKerasでモデル化し、超単純な学習を行いました。単純だけどエッセンスがぎゅーっと詰まったコードです。その中にあった様々な要素の一つで「活性化関数」というのを層に設定しました。前章では半ば機械的に線形関数(linear)を指定しましたが、Kerasには他にも色々な活性化関数があります。ここではKerasがデフォルトで用意してくれている活性化関数を見ていきましょう。
① 使える活性化関数
Kerasの活性化関数は通常文字列で指定します。ではどんな関数を指定できるのか?これはKerasのドキュメントに列挙されています:
列挙すると、
というのが使えるようです(2019.12現在)。と言っても何が何やらだと思います(僕も)。こういう所が敷居高いんですよねぇ…ニューラルネットワークって。なので、噛み砕きましょう。
② 活性化関数解説します
活性化関数の目的はニューロンに入力されてきた刺激を変換する事です。よって、適切な活性化関数を使わないと意図しない値に変換されてしまいます。各活性化関数の性質を知る事は大切なのです。では行きましょう。
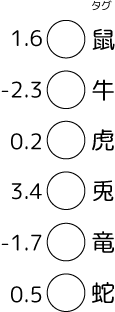
主に出力層で使われ、入力した値を0~1の確率的な値に変換します。出力層が複数のニューロンを持っていて、一つ一つのニューロンが何かのカテゴリーを表しているとした時に、例えば次のような最終入力刺激値が来たとします:
この値が大きい物ほどそのカテゴリーである確率が高い、という結果を得たい時、入力値をそのまま使うとどの位確定的なのか比較する事がちょっと難しくなります。そこで書く数値を確率に変換したくなります。何らかの値の塊を0~1の範囲に変換する方法は幾つかありますが「全部の値を足して各値を割り算する」というのが一般的です(確率密度化)。でもこれは足した値がゼロじゃないとか各数値が正であるなど前提が必要です。そこでsoftmaxでは以下の式で数値をゼロより大きい正の値に変換します:
iはニューロンの番号(=カテゴリー番号)です。こうすると入力値xは正の値yに変換できます。そして全てのカテゴリーに割り振られた入力値の変換したyiを全部足して割り算します:
こうする事で、出力された値はすべて0~1の範囲に収まり、しかもすべてのカテゴリの値の合計がピッタリ1になります。実際上のカテゴリーをsoftmaxで変換すると次のようになります:
このsoftmax変換で「どうやら入力されたのは78.7%の確率で兎のようだよ。次の候補は13.0%で鼠かも」と解釈しやすい数値になりました。この確率の値その物やその差には論理的な根拠は無いのですが、値が小さい物をしっかりふるいにかけられるため、カテゴリー分類をする時にほぼ必須となる変換だったりします。
〇 elu
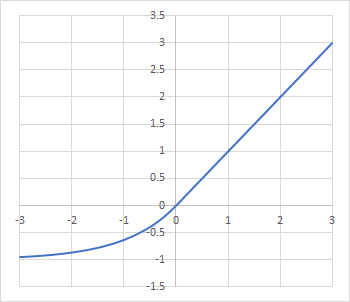
Exponential Linear Units(指数関数的線形ユニット)の略で、元論文はこちら(Fast and Accurate Deep Network Learning by Exponential)になります。式とグラフはこちら:
入力値xが正ならば線形関数と同じように入力値をそのまま採用します。一方でxが負の時にはグラフにあるように-aの値に漸近するマイナス値に変換します。aはマイナス時の漸近ラインを決めるハイパーパラメータで0以上の値を指定します。
なんでこんなメンドクサイ事をしているのかというと、これは重み推定の時に問題となる「勾配消失」に関わっています。勾配消失については後の章でじっくり調査します(するはず!)が、ざっくり言えば活性化関数が返す値がある一定値に張り付くと、前と今の重みによる評価値の差がゼロになってしまい、降りる先を見失ってしまう、という問題です。坂の下に行きたいのに、見渡す限り平面…で途方に暮れる、という感じでしょうか。入力刺激値が正の値にだけ意味を見出したいのだけど、負で一定値にしてしまうと推定に問題が起こるので、緩やかな値にして最適化がちゃんと動くようにしたのがELUという事になりそうです。
〇 selu
Sccaled Exponential Linear Unitsの略で、Kerasが参照している論文はこちら(Self-Normalizing Neural Networks)。リンク先でPDFもダウンロードできます(素敵(^-^))。別リンクはこちら。式とグラフはこんな感じです:
ELUにとても似ていて、ELUお同様に正の値を主に使いたい場合に使用します。ハイパーパラメータとしてλが掛け算されています。ここがScaledの由来なのかなと思います。λによって出力刺激値にスケールをかける事が出来るのでELUよりも調整の自由度が高くなります。ただし(0,0)の所でかくっと不連続に折れます。自由度が高いのならELUじゃなくてこっちを使えば…となりそうですが、パラメータが増えるという事は調整を必要とするという事でもあるので、盲目的にこちらを選択するのではなくてテストしてより良い方を選択するべきかなと思います。
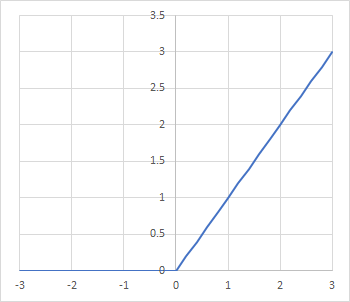
入力値を正の値に変換する活性化関数の一つで、後述するReLU(正規化線形ユニット)に沿う形をしています(平滑化近似と言います)。そこから別名SmoothReLU関数とも呼ばれています:
x>0の所ではxが大きくなる程出力値もxに近寄っていきます。一方入力がマイナス値の時はゼロに漸近していきます。ELUなどと同様に入力がマイナス値の時も何らかのプラスな出力を出したい時などに使います。
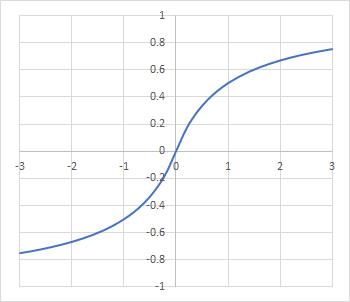
〇 softsign
ニューロンによっては過度な入力刺激値に対して一定の有限な幅に出力刺激値が収まってくれないと困る事もあります。そういう性質を持った活性化関数の一つがsofsignで次のように表現されています:
グラフに表れているように、softsignは正負の刺激に対して対称的です。またどれだけ大きな刺激でも出力が1を超える事はありません。逆にマイナス側は-1を下回る事がありません。正にも負にも触れる刺激の正規化として有用です。
〇 relu
正規化線形関数という部類に入る関数の一つでRectified Linear Unitの略です。ReLUと表記される事が多いです。現在のニューラルネットワークで最もよく使われている活性関数のようです:
非常に分かりやすい形をしています。マイナスの入力値は全部刺激なし(ゼロ)として出力します。正の入力はそのまま流します。これは生物学的な現象にも良くマッチしています(マイナスの刺激というのは本来無い)。ただし負の値が全部ゼロになってしまうので、その情報も必要な場合には使う事が出来ません。
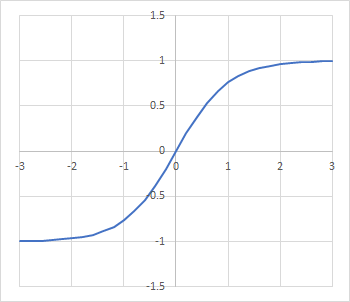
〇 tanh
ハイパボリックタンジェントという三角関数をそのまま活性化関数として使います。softsignと同じで出力刺激値を一定の範囲に収めたい場合に使います:
softsignよりも1や-1への漸近スピードが速いのが特徴です。逆に言えば、ある程度の強い刺激が殆ど同じ刺激として次のニューロンに伝わってしまうため、情報がなめてしまうかもしれません。
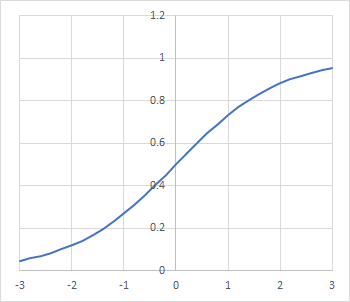
softsignやtanhと同様に入力刺激値を有限の範囲に変換します。ただし前2つと異なり0~1の範囲となります:
入力刺激値を正の値に変換する機能と0~1の有限な幅に変換する機能を併せ持つ活性化関数です。ただし「活性化関数は原点を通した方が良い」という事がだんだんわかって来たため、このまま使うのは少しはばかれるかもしれません。「なら-0.5したらいいんじゃね?」と個人的には思いました(^-^;
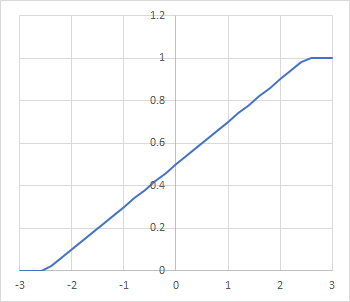
sigmoidを大胆にも直線で近似した活性化関数で、次のように定義されています:
入力刺激値が-2.5よりも小さい場合は出力は全部ゼロに、-2.5~2.5ならば0~1に線形に対応、2.5以上は全部1とします。指数関数の計算が入らないので計算速度が高速化される利点があります。ただし勾配消失が起こりやすいようで扱いには注意が必要かもしれません。
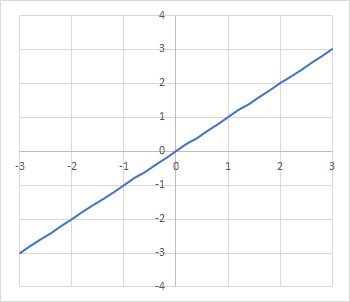
入力刺激値をそのまま出力刺激値とします。要は変換しない活性化関数です。実際は重みwが掛け算されるので、次のニューロンには入力刺激値に比例した値が伝わる事になります:
最も単純な活性化関数の一つですが、実際のニューラルネットワークではあまり使われないようです。
という事で、Kerasでデフォルトで使える活性化関数をざっと見てきました。どうやら活性化関数は、
というタイプに大きくわかれるように見受けられます。この特徴を無視して適当に使ってはいけないですし、これを使えばOKという物でもありません。同じ特徴でも異なる活性化関数がいくつもありますから、それらを差し替えながらより良い出力をするモデルを探すのが大切なんだろうなぁと思います。ただ、それって組み合わせ爆発になりやすいわけで…センスが問われるのかもしれません(^-^;