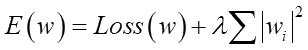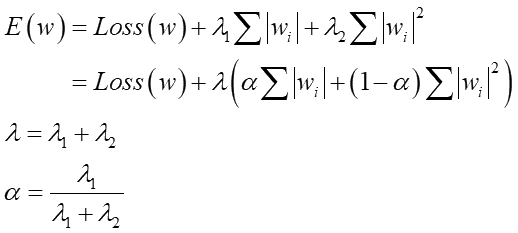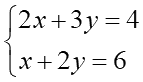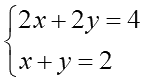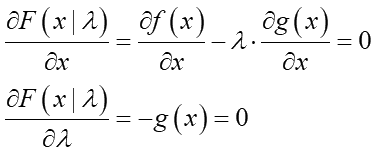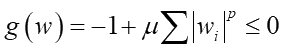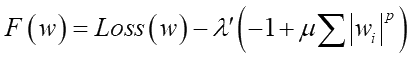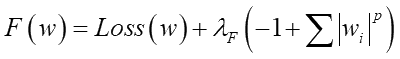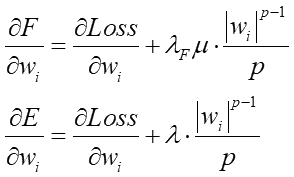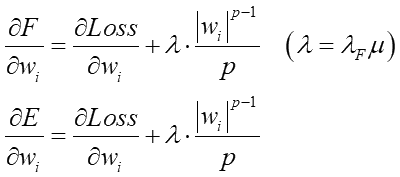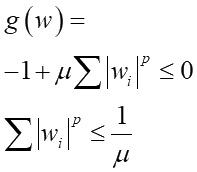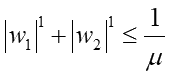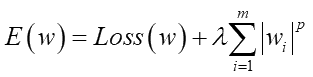
VisualStudio + Python偱僨傿乕僾儔乕僯儞僌
夁妛廗傪杊偖乽惓懃壔乿偲偼丠
(2019. 12. 30)
丂慜偺復偱僪儘僢僾傾僂僩偵傛偭偰夁妛廗傪夞旔偱偒傞帠傪幚尡偱帋偟偰傒傑偟偨丅僪儘僢僾傾僂僩偼憌偵擖偭偰偔傞擖椡抣傪堦帪揑偵僛儘壔偡傞帠偱僨乕僞偺枾搙傪慳偵偡傞張棟偱偟偨丅堦曽偱杮復偱庢傝忋偘傞乽惓懃壔乮Regularization乯乿傕摨條偵夁妛廗傪杊偖庤朄偺堦偮偱偡偑丄偦偺懳徾偼僨乕僞偱偼側偔乽悇掕抣乿偱偡丅乽偁偊偰悇掕偺惛搙傪壓偘傞乿偲偄偆嬃偒偺敪憐偱夁妛廗傪杊巭偟傑偡丅偄偭偨偄偳偆偄偆偐傜偔傝側偺偐丄偠偭偔傝尒偰偄偒傑偟傚偆丅
嘆 昡壙娭悢偵儁僫儖僥傿乕傪梌偊傞
丂僯儏乕儔儖僱僢僩儚乕僋偵尷傜偢偄傢備傞僼傿僢僥傿儞僌偱偼丄堦斒偵僷儔儊乕僞偺悢傪憹傗偟偰偄偔偲摉偰偼傑傝偺巜昗偱偁傞昡壙抣傪偄偔傜偱傕彫偝偔偟偰偄偔帠偑弌棃傑偡丅僷儔儊乕僞偑懡偔側傞掱娭悢偺宍傪帺桼偵嬋偘傞帠偑偱偒傞傛偆偵側偭偰偄偔乮亖帺桼搙偑崅偔側偭偰偄偔乯偐傜偱偡丅偦偆偄偆夁忚側僷儔儊乕僞偵傛偭偰妛廗僨乕僞偵増偄夁偓偰偟傑偄斈梡惈傪幐偭偰偄傞偺偑夁妛廗傪婲偙偟偨儌僨儖偱偡丅偙傟傪夝徚偡傞偵偼僷儔儊乕僞偺悢傪尭傜偣偽椙偄偺偱偡偑丄戲嶳偁傞僷儔儊乕僞偺偳傟傪尭傜偣偽椙偄偐側傫偰丄壗傜偐偺摑寁妛揑側崻嫆偑柍偄尷傝恖偑彑庤偵敾抐弌棃傞暔偱偼偁傝傑偣傫丅傑偟偰僯儏乕儔儖僱僢僩儚乕僋偱梡偄傜傟傞壗愮壗枩偲偄偆僷儔儊乕僞傪庤嶌嬈偱慖暿偡傞帠偼晄壜擻偱偡丅
丂偦偙偱師偺傛偆偵峫偊傑偡丅乽僷儔儊乕僞偑戲嶳偁傞帠偼椙偔側偄丄偡側傢偪掅昡壙偩乿偲丅偦偙偐傜乽婎杮揑偵昡壙抣偱僼傿僢僥傿儞僌偺椙偝傪敾抐偡傞偗偳丄僷儔儊乕僞偑懡偄応崌偼昡壙傪壓偘傞乮亖昡壙抣傪憹傗偡乯乿偲敪憐偡傞偲丄偙傟傑偱偵曄傢傞怴偟偄昡壙偺峫偊曽偵扝傝拝偗傑偡丅偦傟傪幃偱昞偟偨偺偑埲壓偱偡丗
丂Loss偑昡壙娭悢偱丄捠忢偼偙傟傪嵟彫偵偡傞僷儔儊乕僞w傪扵偟傑偡丅偦偙偵僷儔儊乕僞偺愨懳抣傪壗忔偐偟偨抣偺崌寁抣傪懌偟崬傒丄偦傟傪兩偱僗働乕儕儞僌偟傑偡丅偙偺兩偺抣偑0側傜僷儔儊乕僞偺帠偼柍帇偟偨廬棃偺昡壙抣偵側傝傑偡偟丄0傛傝戝偒偔側傟偽僷儔儊乕僞慡懱偺戝偒偝偑昡壙傪壓偘傞帠偵側傝傑偡丅偙偺昡壙偵敱懃傪梌偊傞塃曈戞2崁偺帠傪乽儁僫儖僥傿乕崁乿偲尵偄傑偡丅
丂傕偟Loss昡壙娭悢偺抣偑摨偠偱偁傟偽丄儁僫儖僥傿乕崁偑彫偝偄僷儔儊乕僞僙僢僩偑傛傝椙偄偲偄偆帠偵側傝傑偡丅傕偪傠傫彫偝偄僷儔儊乕僞僙僢僩偑昁偢偟傕惓媊偲偼尷傝傑偣傫丅婎杮偼僼傿僢僥傿儞僌偟偰偄側偄偲昡壙偼壓偑傞栿偱偡偐傜丅尦偺僨乕僞偵婑傝揧偄偮偮傕傛傝彫偝偄僷儔儊乕僞抣傪栚巜偡丅偙傟偵傛傝掱椙偔僼傿僢僥傿儞僌偝傟偰偄偔偺偱偡丅
丂偙偆偄偆乽尦偺娭悢偵懳偟偰捛壛偺忣曬傪梌偊傞帠偱怴偟偄堄枴傪尒弌偟偨傝濨枂偝傪夝徚偟偨傝偡傞乿帠傪惓懃壔偲尵偄傑偡丅惓懃壔偼悢妛揑偵傕椙偔尋媶偝傟偰偄傞戝偒側暘栰偺堦偮偱偡丅偱偼丄僯儏乕儔儖僱僢僩儚乕僋偵梡偄傜傟偰偄傞夁妛廗傪杊偖惓懃壔偺婔偮偐傪徯夘偟傑偡丅
嘇 L1惓懃壔乮LASSO乯
丂忋幃偺傋偒忔p偵偼0埲忋偺幚悢偑擖傝傑偡丅偙傟偼僴僀僷乕僷儔儊乕僞偵側偭偰偄偰恖偑敾抐偟偰悢抣傪寛傔傑偡丅偠傖偠傖偁偳傫側抣傪擖傟傞偺偝丄偲偄偆榖偵側傝傑偡偑丄偙傟偵偼偄偔偮偐戙昞抣偑偁傝傑偡丅偦偺戙昞抣偺偆偪p=1偺傕偺傪乽L1惓懃壔乿偲尵偄傑偡丗
丂偙傟偼暿柤LASSO乮Least Absolute Shrinkage and Selection Operator乯偲傕屇偽傟偰偄傑偡丅偙偺塸岅柤偺擔杮岅栿偼掕傑偭偰偄側偄傛偆偱偡偑丄Shrinkage乮埑弅乯偲Selection乮慖戰乯偲偄偆儚乕僪偵偁傞傛偆偵丄偙偺惓懃壔偵偼僷儔儊乕僞傪慖戰偟僷儔儊乕僞偺悢傪尭傜偡乮師尦埑弅乯岠壥偑偁傝傑偡丅側偤偦偆側傞偐偼偡偛乕偔擹備偄榖偵側傞偺偱屻弎偟傑偡丅偪側傒偵L1偺"L"偼LASSO偺"L"偱偼側偔偰丄挷傋偨斖埻偱偡偑悢妛幰Henri Labesque偺柤慜偑晅偄偨Labesque嬻娫乮Labesque spaces乯偐傜棃偰偄傞傛偆偱偡丅
丂L1惓懃壔傪巊偆偲偁傑傝栶偵棫偭偰偄側偄僷儔儊乕僞w偑愊嬌揑偵僛儘乮柍岠壔乯傊捛偄傗傜傟丄堄枴偺嫮偄僷儔儊乕僞偩偗偑巆偭偰偄偒傑偡丅偙傟偵傛傝幚幙揑側僷儔儊乕僞悢偑尭傝傑偡丅偙傟傪乽儌僨儖偑僗僷乕僗乮慳乯偵側傞乿側偳偲尵偄傑偡丅慳偵側偭偨儌僨儖偼嵶偐偄晹暘偺昞尰椡偑壓偑傞偨傔丄慡懱揑偵廮傜偐偄宍忬偵側傝夁妛廗忬懺傪扙偣傑偡丅偦偺惈幙偐傜僲僀僘傪彍嫀偟偰戝愗側強傪晜偒挙傝偵偡傞惓懃朄偲偟偰椙偔巊傢傟偰偄傑偡丅
嘊 L2惓懃壔乮Ridge乯
丂傋偒忔抣傪p=2偲偡傞偲L2惓懃壔偲偄偆傕偺偵側傝傑偡丅暿柤Tikhonov惓懃壔乮Ridge惓懃壔乯偲傕尵偄傑偡丗
丂L1惓懃壔偲堘偄丄L2惓懃壔偼偁傑傝栶偵棫偭偰偄側偄僷儔儊乕僞傕妶梡偟傑偡丅屻弎偡傞僀儊乕僕恾傪尒傞偲傛傝慛柧偵傢偐傝傑偡偑丄偞偭偔傝尵偊偽塭嬁椡偺嫮偄僷儔儊乕僞偺岠壥傪彮偟壓偘偰偦偺暘嵶晹偺昞尰偵夞偡摥偒傪偟傑偡丅偙傟偵傛傝夁妛廗偱偼柍偄偗偳傕嵶晹傕偁傞掱搙嵞尰偡傞儌僨儖偲側傝傑偡丅偦偺偨傔L1惓懃壔偵傛傞儌僨儖傛傝傕惛搙偑崅偄儌僨儖偵側傝傑偡丅惛搙偑崅偄偲偄偆偺偼傛傝桪廏偲偄偆帠偱偼柍偔偰乽嵶晹偑峫椂偝傟偰偄傞乿偲偄偆堄枴偱偡丅
嘋 Elastic net惓懃壔乮L1/L2惓懃壔乯
丂L1惓懃壔偼僷儔儊乕僞傪尭傜偡丄L2惓懃壔偼惛搙傪忋偘傞惓懃壔偱偟偨丅偙偺椉幰偺椙偄強庢傝傪偟偨偺偑Elastic net惓懃壔偱偡丗
儁僫儖僥傿乕崁偑L1偲L2偺2偮偵側偭偰偄偰丄偦傟偧傟傪懌偟崌傢偣偰偄傑偡丅兩1偺抣傪憹傗偣偽L1惓懃壔偺岠壥偑弌偰偒偰丄兩2傪憹傗偡偲L2惓懃壔偺岠壥偑弌偰偒傑偡丅憃曽偺憡懳揑側戝偒偝偱岠壥偑曄傢傝傑偡丅
嘍 僴僀僷乕僷儔儊乕僞兩偺抣
丂忋幃偺兩偼恖偑梌偊傞僴僀僷乕僷儔儊乕僞偺堦偮偱偡丅抣傪戝偒偔偡傞傎偳昡壙娭悢偵懳偡傞儁僫儖僥傿乕偺岠壥偑崅偔側傞偨傔廳傒w偺抣傪慡懱揑偵彫偝偔偡傞嶌梡偑嫮偔側偭偰偄偒傑偡丅偦傟偼寢壥偲偟偰儌僨儖慡懱偺婲暁傪彫偝偔偟偰偟傑偆偨傔丄偳傫偳傫儌僨儖偑濨枂偵側偭偰偟傑偄傑偡丅偮傑傝抣偑戝偒偄掱夁妛廗偐傜墦偔側傝傑偡偑丄戝偒夁偓傞偲偦傕偦傕儌僨儖偲偟偰巊偄暔偵側傜側偔側偭偰偄偒傑偡丅側偺偱壖妛廗偱掱椙偄抣偵挷惍偡傞昁梫偑偁傝傑偡丅
嘍 Keras偱偺L1丄L2惓懃壔愝掕
丂Keras偵偼奺憌偛偲偵L1丄L2媦傃L1L2惓懃壔傪愝掕偱偒傑偡丗
model.add( keras.layers.Dense( units=100, activation="relu", kernel_regularizer=keras.regularizers.l1(0.01), input_shape=(1,) ) )
儗僀儎乕嶌惉帪偵kernel_regularizer偵惓懃僆僽僕僃僋僩傪搉偟傑偡丅僨僼僅儖僩偱嶌惉壜擻側惓懃僆僽僕僃僋僩偼埲壓偺捠傝偱偡丗
keras.regularizers.l1(0.) #L1惓懃壔
keras.regularizers.l2(0.) #L2惓懃壔
keras.regularizers.l1_l2(l1=0.01, l2=0.01) #L1/L2惓懃壔暪梡
堷悢偼儁僫儖僥傿乕學悢兩偱偡丅
丂偲偄偆帠偱丄偙偙傑偱偑惓懃壔偺奣梫偲椙偔棙梡偝傟傞惓懃壔偺偞偭偔傝偲偟偨愢柧偱偟偨丅岠壥傪棟夝偟偰巊偆暘偵偼偙偙傑偱偺偍榖偱帠懌傝傑偡丅偨偩怓乆側乽壗屘丠乿偑戲嶳偁傞偙偺惓懃壔丅偙偙偐傜愭偼傕偆彮偟嵶偐側悢妛揑側攚宨偵偮偄偰尒偰偄偒傑偡丅嫽枴偺偁傞曽偩偗偳偆偧(^-^;
丂埲壓偺棟孅偼opabinia2條偺乽婡夿妛廗偵徻偟偔側傝偨偄僽儘僌乿傪偼偠傔條乆側僒僀僩偺忣曬傪嶲峫偵偝偣偰捀偒傑偟偨丅奺僒僀僩條惤偵偁傝偑偲偆偛偞偄傑偡m(_ _)m
曗懌嘆 惓懃壔偲偼丠
丂巹偑偙偺復傪彂偔偵偁偨傝丄傑偢嵟弶偵巚偭偨偺偼乽惓懃偭偰壗丠乿偱偟偨丅抦傜側偄棫応偐傜偡傞偲丄堄枴傪慡慠悇應弌棃側偄帤柺偱偡傛偹(^-^;丅Wikipedia偺乽惓懃壔乿傪尒偰傒傞偲丄
悢妛丒摑寁妛丒寁嶼婡壢妛偵偍偄偰丄摿偵婡夿妛廗偲媡栤戣偵偍偄偰丄惓懃壔乮偣偄偦偔偐丄塸: regularization乯偲偼丄晄椙愝掕栤戣傪夝偄偨傝夁妛廗傪杊偄偩傝偡傞偨傔偵丄忣曬傪捛壛偡傞庤朄偱偁傞丅儌僨儖偺暋嶨偝偵敱懃傪壢偡偨傔偵摫擖偝傟丄側傔傜偐偱側偄偙偲偵敱懃傪偐偗偨傝丄僷儔儊乕僞偺僲儖儉偺戝偒偝偵敱懃傪偐偗偨傝偡傞丅
偲偁傝傑偡丅擄偟偄儚乕僪偑暲傫偱偄傑偡偑丄惓懃壔偲偄偆偺偼偳偆傗傜乽晄椙愝掕栤戣乿傪夝偔庤朄偱偁傞丄偲偄偆偺偼撉傒庢傟傑偡丅偱丄偦偺晄椙愝掕栤戣偭偰壗傛丠偲偄偆榖偱偡丅偙傟丄尩枾偝偵栚傪嵋傟偽幚偼拞妛峑偺悢妛偱傕傢偐傞妱偲娙扨側帠側傫偱偡(^-^)
丂偄偒側傝偱偡偑師偺楢棫曽掱幃傪夝偄偰傒傑偟傚偆丗
丂偙傟偼娙扨偱偡傛偹丅2偮栚偺幃傪-2攞偟偰忋偺幃偲懌偟嶼偡傞偲 y = 8 偑弌偰偒偰丄偦傟傪2偮栚偺幃偵戙擖偡傟偽
x = -10偑嶼弌偱偒傑偡丅偙偺傛偆偵夝偑堦堄偵掕傑傞傛偆側栤戣傪乽椙愝掕栤戣乮well-posed problem乯乿偲尵偄傑偡丅偦偟偰夝偑堦堄偵掕傑傞帠傪乽惓懃偱偁傞乿偲尵偄傑偡丅
丂偱偼忋傒偨偄側楢棫曽掱幃偱幃偑2杮偁傟偽忢偵夝偑媮傑傞偐偲偄偆偲丄昁偢偟傕偦偆偲偼尷傝傑偣傫丅師偺楢棫曽掱幃傪尒偰壓偝偄丗
丂愭掱偲摨條偵2偮栚傪-2攞偟偰忋偺幃偲懌偡偲乧偁傟傟丄x偲y偑椉曽懪偪徚偝傟偰徚偊偰偟傑偄傑偡丅偠傖偠傖偁2偮栚偐傜
y = 2 - x 偲偟偰偦傟傪忋偺幃偵戙擖偟偰傕乧傗偭傁傝x傕摨帪偵徚偊偰偟傑偄傑偡丅壗屘偍偐偟側帠偵側偭偰偟傑偆偺偐丠偦傟偼幃偑2偮偁傞傛偆偵尒偊偰幚偼1偮偟偐柍偄偐傜偱偡丅忋偺幃偺椉曈傪2偱妱傞偲壓偺幃偲堦弿偵側偭偰偟傑偄傑偡傛偹丅偙偺x
+ y = 2傪枮偨偡x偲y偺慻傒崌傢偣偼柍尷偵偁傝傑偡丅夝偑堦堄偵掕傑傜側偄偺偱乽惓懃偱偼柍偄乿偺偱偡丅偦偟偰偙偆偄偆夝偑堦堄偵掕傑傜側偄栤戣偺帠傪乽晄椙愝掕栤戣乿偲尵偄傑偡丅
丂忋偺傛偆側晄椙愝掕栤戣偵側偭偰偄傞楢棫曽掱幃偼偦偺傑傑偱偼夝偑掕傑傝傑偣傫丅偱傕丄傕偟乽x
= 3偩傛乿偲捛壛偺忣曬偑偁偭偨傜偳偆偱偟傚偆丅偨偪傑偪 y = -1 偲夝偗偰偟傑偄傑偡丅晄椙愝掕栤戣偼偦偺傑傑偱偼夝偑掕傑傝傑偣傫偑乽x
= 3偩傛乿偺傛偆偵乽忣曬傪捛壛偡傟偽乿夝偗傞傛偆偵側傞帠偑偁傝傑偡丅偙偺乽忣曬傪捛壛偡傞帠偱惓懃偱側偄栤戣傪夝偗傞傛偆偵偡傞帠乿傪惓懃壔偲尵偄傑偡丅
丂堦曽偱丄僯儏乕儔儖僱僢僩儚乕僋偱偼僷儔儊乕僞悇掕偼晛捠偵偱偒傑偡丅偮傑傝尦乆偺娭悢偵偪傖傫偲嵟揔夝偑懚嵼偟傑偡丅偱傕丄偙偺復偱偍榖偟偰偒偨傛偆偵偦偺嵟揔夝偑帪偵乽朷傑偟偔側偄乿偺偱偡乮仼夁妛廗乯丅側偺偱乽儁僫儖僥傿乕崁乿偲偄偆忣曬傪捛壛偟偰朷傑偟偄怴偨側夝傪媮傔傞娭悢傪嶌傝傑偟偨丅忣曬傪捛壛偡傞帠偱乮朷傫偱偄傞乯夝傪媮傔傞帠偑偱偒傞傛偆偵側傞偺偱丄偙傟傕惓懃壔偲尵偊傑偡丅
曗懌嘇 儔僌儔儞僕儏偺枹掕忔悢朄
丂惓懃壔偵偮偄偰僀儊乕僕弌棃偨強偱丄朻摢偱弌偰偒偨惓懃壔偺幃傪傕偆堦搙尒偰傒傑偡丗
偙偺E(w)傪嵟彫偵偡傞傛偆側廳傒w偑朷傓夝偱偡丅偮傑傝偙傟偼乽嵟彫壔栤戣乿偵側偭偰偄傑偡丅偨偩丄尦乆偺Loss(w)傕嵟彫側偺偑僄儔僀偲偄偆嵟彫壔栤戣偱偟偨丅偙偺尦偺嵟彫壔栤戣偐傜尒傞偲儁僫儖僥傿乕崁偼乽惂栺乿偵側偭偰偄傑偡丅偙偺傛偆側乽偁傞惂栺偺拞偱嵟彫乮嵟戝乯偲側傞僷儔儊乕僞傪媮傔傞乿偲偄偆偺偼乽惂栺忦審晅偒嵟揔壔栤戣乿偲屇偽傟偰偄傑偡丅偦偺惂栺忦審晅偒嵟揔壔栤戣傪夝偔庤朄偲偟偰戝曄椙偔抦傜傟偰偄傞偺偑儔僌儔儞僕儏偺枹掕忔悢朄偱偡丅偙傟偵偮偄偰偼乑亊揑悢妛偺偍晹壆偦偺俀乽嬌抣傪媮傔傞儔僌儔儞僕儏偺枹掕忔悢朄乿偱徻偟偔愢柧偟偰偍傝傑偡丅徻偟偔偼儕儞僋愭偺復傪偛棗捀偔偲偟偰丄夝偔嬝摴傪偞偭偲偍偝傜偄偟傑偡丅
丂僷儔儊乕僞x偺摦偗傞斖埻偱偁傞惂栺忦審傪g(x)=0偲偟丄偙傟偲f(x)偲偱師偺傛偆側怴偟偄娭悢傪嶌傝傑偡丗
偙偺幃偼儔僌儔儞僕儏偺幃偲屇偽傟傑偡丅兩偼惂栺忦審傪怢傃弅傒偝偣傞僗働乕儖抣偱偡乮堄枴崌偄偵偮偄偰偼愭偺儕儞僋愭偱愢柧偟偰偄傑偡乯丅偙偺娭悢F(x)傪x偲兩偦傟偧傟偱曃旝暘偟丄偦偺抣偑僛儘偱偁傞偲偄偆楢棫曽掱幃傪嶌傝傑偡丗
偙偺旝暘幃偼枹抦偺曄悢偑x偲兩丄幃偺杮悢傕2杮側偺偱乮憃曽偑堎側傞幃偵側偭偰偄傟偽乯x傕兩傕堦堄偵媮傔傞帠偑弌棃傑偡丅偦偟偰丄偦偙偱媮傔偨x偑惂栺忦審傪枮偨偟偨拞偱偺f(x)偺嬌抣乮嬌彫or嬌戝乯偵側傝傑偡丅乽偼丠側傫偱両丠乿偲巚偭偨曽偼乽嬌抣傪媮傔傞儔僌儔儞僕儏偺枹掕忔悢朄乿傪偛棗偔偩偝偄(^-^;丅棟孅偼偝偰抲偒偦偆偄偆惂栺壓偺嬌抣傪媮傔傞帠帺懱偼娙扨偱偡丅
曗懌嘊 儔僌儔儞僕儏偺枹掕忔悢朄偵増偭偨惓懃偺幃
丂曗懌嘇偱偺尦娭悢f(x)傪Loss娭悢偲偟丄惂栺忦審偲偟偰師偺傛偆側g(x)傪峫偊傑偡丗
偙傟偼媮傔傞僷儔儊乕僞偺崌寁抣傪兪攞偟偨抣偑崅乆1偵側傞丄偲偄偆傛偆側惂栺忦審偱偡丅惂栺忦審偑晄摍幃偵側偭偰偄傑偡丅偙偆偄偆偺傪乽晄摍幃惂栺晅偒嵟揔壔栤戣乿偲尵偄傑偡丅偙傟偵偮偄偰偼乽惂栺忦審偑晄摍幃偱偺儔僌儔儞僕儏偺枹掕忔悢朄乿偵愢柧傪忋偘傑偟偨丅戝偒偔擄偟偔側傞偙偲偼柍偔偰丄f(x)偺嬌抣偑g(w)偺撪懁偵偁傞応崌偼扨側傞惂栺側偟偺嬌抣栤戣丄奜懁偵偁傞応崌偼g(w)=0偲偟偨儔僌儔儞僕儏偺枹掕忔悢朄栤戣偲側傝傑偡丅偙偙偐傜儔僌儔儞僕儏偺幃傪嶌傞偲丄
偙偆側傝傑偡丅偙偙偱丄Loss娭悢偼側傞傋偔彫偝偔側傞乮偍榦偺掙傪扵偡乯栚揑側偺偱丄撌墯偼偟偰偄傑偡偑婎杮壓偵撌偺娭悢偲尵偊傑偡丅偦偆偄偆壓偵撌偺娭悢偺応崌偱嬌抣偑g(x)偺斖埻奜偵偁傞応崌丄儔僌儔儞僕儏幃偺兩偺抣偼僛儘枹枮偺儅僀僫僗抣偵側傞帠偑抦傜傟偰偄傑偡乮KTT忦審乯丅傛偭偰忋偺-兩'=兩F乮兩F>0乯偲抲偒捈偡偲丄
偙偺傛偆偵兩偺晞崋傪斀揮弌棃傑偡乮偨偩偟兩F>0乯丅偙偺幃丄朻摢偺惓懃壔幃E(w)偲椙偔帡偰偄傑偡傛偹丅
丂偙偺F(w)偺嵟彫抣傪媮傔傞偵偼僷儔儊乕僞w偲兩偺曃旝暘偑僛儘偲側傞w傗兩傪扵偟傑偡丅摨偠傛偆偵惓懃壔幃E(w)偺嵟彫抣傕偦偺曃旝暘幃偑僛儘偲側傞w傪尒偮偗傑偡丅偦偙偱丄椉幰偺曃旝暘幃傪楍嫇偟偰傒傑偡丗
憡摉偵偦偭偔傝偱偡丅桞堦堘偆偺偑戞2崁偺學悢丅忋偺儔僌儔儞僕儏偺幃偑兩F兪側偺偵懳偟偰壓偺惓懃壔幃偼兩偺傒偱偡丅偦偙偱忋偺學悢傪堦偮偵傑偲傔偰偟傑偄傑偟傚偆丗
傑偭偨偔堦弿偵側偭偰偟傑偄傑偟偨両偙傟偼乽惓懃壔幃E(w)偺嬌抣栤戣偼丄g(w)亝0偺惂栺忦審壓偱偺Loss娭悢偺嬌抣栤戣偲堦弿乿偲偄偆帠傪堄枴偟偰偄傑偡丅偨偩偪傚偭偲拲堄偑偁傝傑偡丅儔僌儔儞僕儏幃偺兩偼枹抦悢偲偟偰悇掕偡傞抣偱偡丅堦曽偱惓懃壔幃偺兩偼僴僀僷乕僷儔儊乕僞偲偟偰恖偑梌偊傑偡丅乽偁傟丠偠傖偀忋偲壓偺兩偼堘偆抣偵側傞傫偠傖乧丠乿偲巚偄傑偟偨丄巹偼(^-^;丅偙偙丄惁偄擸傫偩強偱偡丅偙傟偼師偺傛偆側夝庍偱偟偨丅
丂忋偺儔僌儔儞僕儏幃偱悇掕偝傟傞偺偼兩F偱偡丅偦傟偼妋偐偵壓偺惓懃幃偱恖偑揔摉偵梌偊偨兩偲偼堎側傝傑偡丅偱傕丄兩F偺抣偵懳墳偡傞傛偆偵兪偺抣傪曄偊傟偽椉幰偺兩偼偄偮傕堦弿偵弌棃傑偡丅偱偼兪偲偼壗偩偭偨偐丠
偙傟偼廳傒偺傋偒忔偺崌寁抣偑1/兪埲壓偵側傞偲偄偆斖埻傪昞偡抣偱偡丅偮傑傝丄偙偺惓懃壔幃E(w)偱偺嬌抣栤戣偲偄偆偺偼丄忋偺傛偆側惂栺斖埻傪兩偺抣偵懳墳偡傞傛偆偵戝偒偔偟偨傝彫偝偔偟偨傝帺摦揑偵挷惍偟偰椙偄姶偠偺棊偲偟偳偙傠傪扵偭偰偔傟偰偄傞偺偱偡両側偺偱丄僴僀僷乕僷儔儊乕僞偲偟偰梌偊偰偄傞兩偺抣偑彫偝偔側傞掱偦偺媡悢偺娭學偵側偭偰偄傞忋偺斖埻偼峀偔側傝傑偡丅偨偩悇掕抣偱偁傞兩F偼捈愙偼暘偐傝傑偣傫偺偱丄忋偺儈儏乕偺斖埻傪捈愙堄幆偡傞帠偼偪傚偭偲擄偟偄偐側偲巚偄傑偡丅偩偐傜壖妛廗偱兩偺抣傪挷惍偡傞僥僗僩傪偡傞昁梫偑偁傝傑偡丅
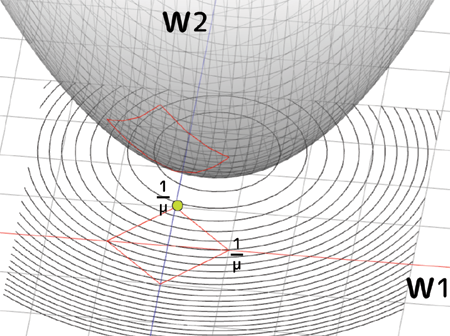
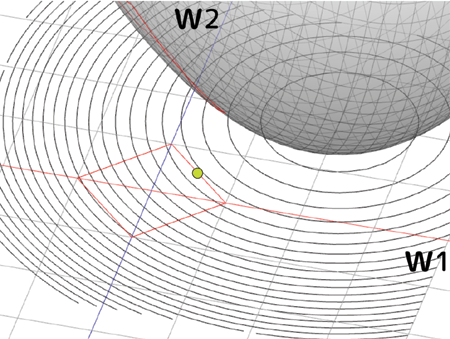
曗懌嘋 L1惓懃壔偺僀儊乕僕
丂嘊傑偱偱偙偺惓懃幃E(w)偑忋偺g(w)亝0傪惂栺忦審偲偟偨儔僌儔儞僕儏幃偲堦弿偱偁傞帠偑暘偐傝傑偟偨丅偱偼p=1偺帪偺儁僫儖僥傿乕偱偁傞L1惓懃壔偼偳偆偄偆暔偵側傞偐僀儊乕僕偟偰傒傑偟傚偆丅妋偐L1惓懃壔偼塭嬁偑彫偝偄僷儔儊乕僞傪庢傝彍偔岠壥偑偁傞偺偱偟偨丅側偤偦偆偄帠偵側傞偐傕僀儊乕僕傪尒傞偲暘偐傝傑偡丅恖偑僌儔僼偲偟偰妋擣偱偒傞偺偼2曄悢傑偱側偺偱丄廳傒w1丄w2偺2偮偱峫偊偰傒傑偡丅
丂Loss娭悢偼壓偵撌偺宍忬傪偟偰偄傞乮偲峫偊傞乯偺偱丄(w1,w2)偵懳偟偰僾儘僢僩偡傞偲僷儔儃儔揑側宍忬偵側傝傑偡丅偦傟偵懳偟偰L1惓懃壔偺惂栺忦審g(w)偼師幃偺傛偆偵側傝傑偡丗
偙傟傜傪僌儔僼偵僾儘僢僩偡傞偲師偺傛偆偵側傝傑偡丗
丂墶幉偑w1丄廲幉偑w2丄3D側僌儔僼偑尦偺Loss娭悢偱丄愒偄巐妏榞偑L1惓懃壔偺惂栺忦審偺斖埻偱偡丅摍崅慄偼Loss娭悢偺抣傪昞偟偰偄傑偡丅傕偟惂栺忦審偑柍偗傟偽摍崅慄偺墌偺拞怱偑偍榦偺掙側偺偱丄w1丄w2偼偦偺曈傝偲偟偰悇掕偝傟傞帠偵側傝傑偡丅偟偐偟L1惓懃壔偺惂栺忦審偑偁傞応崌丄w1丄w2偼愒偄巐妏榞偺撪懁偱偟偐懚嵼偟偰偼偄偗側偄偺偱丄恾偺椢偺娵報偺強偑嵟彫抣偲偟偰嶼弌偝傟傞帠偵側傝傑偡丅偙偺椢報偱偺w1偺抣偑僛儘偵側偭偰偄傞偺偵拲栚偟偰壓偝偄丅摍崅慄偑w2幉偵懳偟偰偼悅捈婥枴偵側偭偰偄傞偺偵懳偟丄w1幉偵懳偟偰偼暯峴偭傐偔側偭偰偄傑偡丅偙偺堊巐妏宍偺妏偑摍崅慄偵巋偝傞偺偱丄w2偑嵦戰偝傟w1偼僛儘偵側傞丄偲偄偆嶌梡偑婲偙傝傑偡丅偙傟偑L1惓懃壔偺僷儔儊乕僞慖戰嶌梡偱偡丅
丂傕偪傠傫偍榦偺掙偺埵抲偵傛偭偰偼w1傕嵦戰偝傟傞忬嫷偑偁傝偊傑偡丗
Loss娭悢偺嵟彫抣偑忋恾偺傛偆側埵抲偵偁傞帪丄惂栺忦審偺巐妏偄榞偺曈偺曽偑妏傛傝傕掅偔側傝傑偡丅偙偺応崌偼w1傕w2偺偳偪傜傕旕僛儘側抣偲偟偰嵦戰偝傟傑偡丅偳偪傜傕儌僨儖偵椙偔塭嬁偟偰偄傞偲偄偆帠偱偡偹丅
丂僴僀僷乕僷儔儊乕僞偲偟偰梌偊傞兩偺抣傪彫偝偔偡傞丄偮傑傝儁僫儖僥傿乕偺岠壥傪彫偝偔偡傞偲丄忋偺愒榞偺斖埻偑偳傫偳傫峀偑偭偰偄偒傑偡丅傕偟偦偺斖埻撪偵偍榦偺掙偑擖偭偰偟傑偆偲丄傕偼傗儁僫儖僥傿乕岠壥偼幐傢傟偰偟傑偄,丄僷儔儊乕僞偺悢偵傛偭偰偼夁妛廗壔偟偰偟傑偆帠偵側傝傑偡丗
側偺偱兩偺挷惍偼惓懃壔傪巊偆応崌偵偼嬌傔偰廳梫偱偡丅偟偐偟偳偆偄偆斖埻偑揔惓偱偁傞偐偼儌僨儖偵傛偭偰慡偔堎側傝傑偡偺偱丄僥僗僩妛廗傪孞傝曉偟偰挷惍偡傞昁梫偑偁傝傑偡丅
丂偲偄偆帠偱僯儏乕儔儖僱僢僩儚乕僋偺惓懃壔偺僶僢僋儃乕儞偵偮偄偰彮偟怺偔孈傝壓偘偰傒傑偟偨丅L1/L2惓懃壔偼婎杮揑側暔偱偼偁傝傑偡偑丄偮偔偯偔椙偔尋媶偝傟偰偄傞側偀偲姶怱偟偰偟傑偄傑偡丅懠偵傕條乆側惓懃壔偑峫埬偝傟偰偄傑偡丅偦偺曈傝偼偄偢傟傑偨(^-^;